FieldDeclaration = _typeMemberPrefix, Semicolon; MethodDeclaration = _typeMemberPrefix, ParameterList, MethodBody; PropertyDeclaration = _typeMemberPrefix, PropertyBody; _typeMemberPrefix = [Attributes], [Modifiers], Type, Identifier;

このトピックでは、Syntax Parsing Engine が実施する構文ツリーのプルーニングについて説明します。
このトピックを理解するためには、以下のトピックを理解しておく必要があります。
組織としては、エラー処理ビヘイビアー、あいまいさの解決、またはその他の理由のために文章校正ライターが、最終的な構文ツリーにノードとして含めるべきでないその他の非終端記号を文章校正の定義に含める必要があります。これらの記号を構文ツリーから除外するために使用するプルーニングは 2 種類あります。
構文ツリープルーニングの種類を変更するには、 Grammar.SyntaxTreePruningMode プロパティを使用し、 SyntaxTreePruningMode 型の値に設定します。デフォルトでは、どちらのプルーニングモードも有効になります。
多くの場合、特定の「ヘルパー」非終端記号を文章校正定義に含め、文章校正の複雑さを軽減し、EBNF ファイル内で共通のパターンが繰り返されないようにできます。多くの場合、これらの非終端記号は構文ツリーのノードを関連づけておらず、そのため以下の例に示すように、最初の文字にアンダースコアを使用して名前をつけることにより除外できます。
FieldDeclaration = _typeMemberPrefix, Semicolon; MethodDeclaration = _typeMemberPrefix, ParameterList, MethodBody; PropertyDeclaration = _typeMemberPrefix, PropertyBody; _typeMemberPrefix = [Attributes], [Modifiers], Type, Identifier;
構文ツリーが名前に基づいてプルーニングされる場合、アンダースコアで開始するすべての非終端記号はツリー内でノードとして表れることはなく子ノードはツリー内の次に含められる親ノードの子に昇進します。
オペレータールールを定義する場合にグローバルなあいまいさを回避する共通の方法は、優先順位の低い操作が優先順位の高い操作を「所有」するようにルールを決めることです。これにより、優先順位の高い操作はオペランドでグループ化されます。この取り決めの副作用は、自身で参照する識別子などより共通の単純な表現が非常に濃厚な構文ツリーにつながりかねないことです。識別子ノードは、それぞれ優先順位の低いレベルを表すノードによって所有されます。
たとえば、「x = y」のような単純な式が以下のような構文ツリー構造につながる可能性があります。
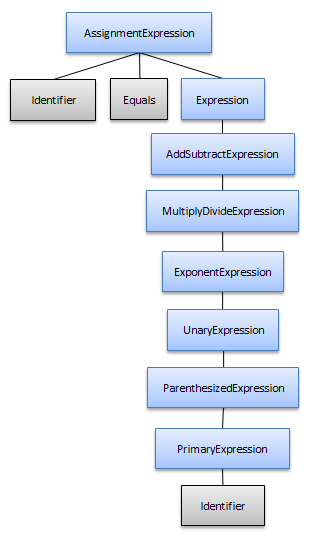
ただし、「子に基づく」プルーニングでは、構文ツリーは代わりにこのように見えます。
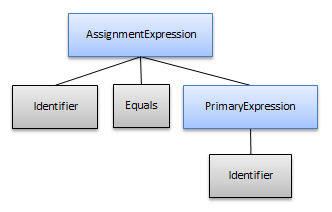
このプルーニングモードは、単一の非終端記号ノードを所有する非終端記号ノードを除外します。子の非終端記号ノードは、その後、次に含められるアンカーノードの子に昇進します。
このトピックの追加情報については、以下のトピックも合わせてご参照ください。